Теория и реализация языков программирования
Таблицы расстановки со списками
Только что описанная схема страдает одним недостатком - возможностью переполнения таблицы. Рассмотрим ее модификацию, когда все элементы, имеющие одинаковое значения (первичной) функции расстановки, связываются в список (при этом отпадает необходимость использования функций hiдля i

Вначале таблица расстановки пуста (все элементы имеют значение NULL). При поиске идентификатора Id вычисляется функция расстановки h(Id) и просматривается соответствующий линейный список. Поиск в таблице может быть описан следующей функцией:
struct Element {String IdentP; struct Element * Next; }; struct Element * T[N];
struct Element * Search(String Id) {struct Element * P; P=T[h(Id)]; while (1) {if (P==NULL) return(NULL); else if (IdComp(P->IdentP,Id)==0) return(P); else P=P->Next; } }
Занесение элемента в таблицу можно осуществить следующей функцией:
struct Element * Insert(String Id) {struct Element * P,H; P=Search(Id); if (P!=NULL) return(P); else {H=H(Id); P=alloc(sizeof(struct Element)); P->Next=T[H]; T[H]=P; P->IdentP=Include(Id); } return(P); }
Процедура Include заносит идентификатор в таблицу идентификаторов. Алгоритм иллюстрируется рис. 7.4.
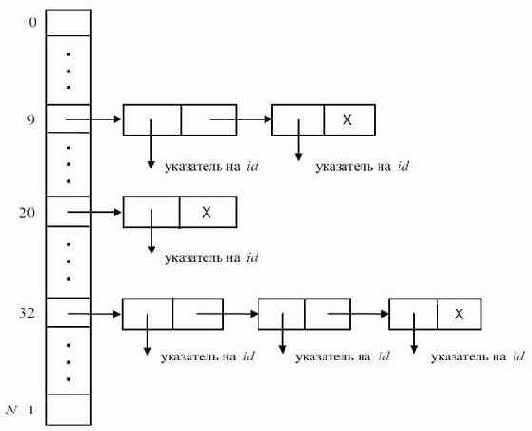
Рис. 7.3.
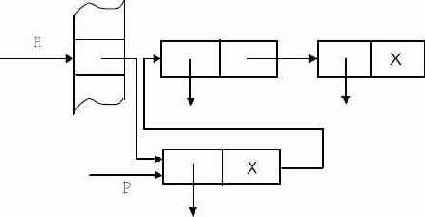
Рис. 7.4.